


Jeder kennt die Botschaft: Unternehmen sollen nicht nur ihre Prozesse digitalisieren und automatisieren, sondern ihre Daten auch für Innovationen und die Erhaltung ihrer Wettbewerbsfähigkeit «vergolden». Von Data Mining über Big Data bis hin zu Data Science und Data Analytics scheint nun mit Artificial Intelligence (AI) in Sachen Schlagwörter der Zenit erreicht. Noch nie war die Begeisterung für künstliche Intelligenz (KI) so gross.

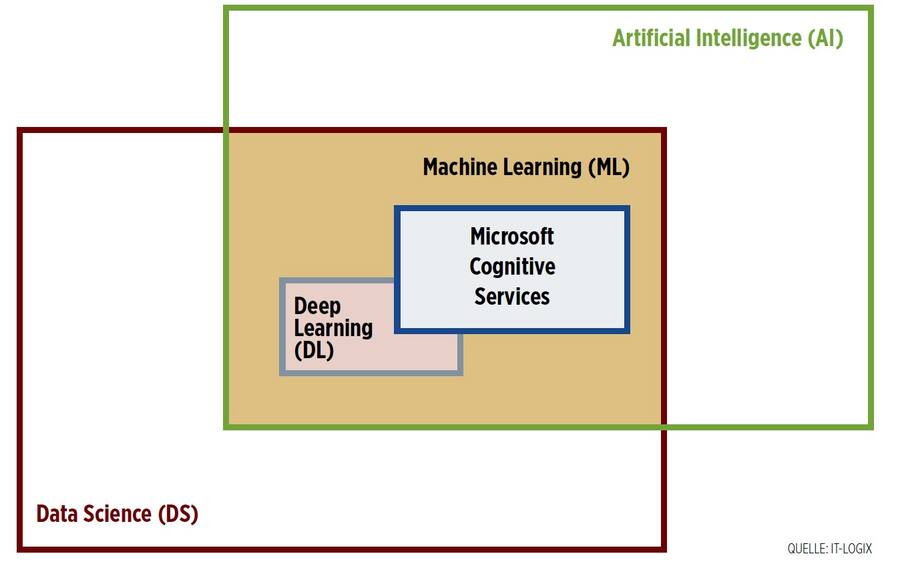
Einer aktuellen Studie von IDC zufolge soll der Markt für KI in Europa bis 2023 auf 21 Milliarden Dollar anwachsen – also auf etwa 3 Prozent der gesamten Ausgaben für Informations- und Kommunikationstechnik (ITK). Während die Angst vor KI der Hoffnung in sie gewichen ist, hat allerdings eine gewisse Verwirrung der verwendeten Begriffe Einzug gehalten. Im Folgenden sollen die trendigsten Begriffe (siehe Grafik) erklärt und in einen praktischen Kontext gestellt werden. Schon in den 1950er Jahren beschäftigte sich der Informatiker Alan Turing mit KI. Ein Test (siehe Box) sollte zeigen, ob eine Maschine Intelligenz besitzt. Um es gleich vorwegzunehmen: Den Test hat bis dato noch keine Maschine bestanden. Aber heute ist KI ein Teilgebiet der Informatik mit vielen Überschneidungen in andere Disziplinen wie Linguistik, Psychologie, Neurologie und Philosophie. Ziel ist die Herstellung eines intelligenten Agenten oder Systems. Als Dateneingaben und Zwischenzustände dienen Vorwissen über die Umgebung (beispielsweise eine Karte), aber auch erlerntes Wissen, Testfälle und so weiter. Die zu erreichenden Ziele sind üblicherweise mit Prioritäten und Wichtigkeiten versehen.
Ein solches System kann Beobachtungen über die Umgebung und sich selbst machen und daraus Schlüsse ziehen, beispielsweise bezüglich Lernen. Aufgrund dieser «Eingaben» berechne der Agent als Ausgabe seine nächste Aktion, schreibt Manfred Schmidt-Schauss, Professor an der Johann-Wolfgang-Goethe-Universität in Frankfurt am Main. Die künstliche Intelligenz ist also ein System, das aus einem Regelwerk besteht, das zum Teil auch selbst aus Daten gewonnen, das heisst «gelernt » wurde. Es optimiert die Zielerreichung und hat durch Beobachtung und Bewertung seiner selbst die Möglichkeit, aus den eigenen Fehlern zu lernen.
Diskussion Der Test war zunächst eine theoretische Skizze. Sie wurde erst später genauer und konkreter ausformuliert, nachdem die künstliche Intelligenz zu einem eigenständigen akademischen Fachgebiet geworden war. Seither dient der Test in der Diskussion über KI wiederholt dazu, den Mythos denkender Maschinen zu beleben. Ursprung Mit dem sogenannten Turing- Test formulierte der britische Logiker und Informatiker Alan Turing im Jahr 1950 eine Idee, wie man feststellen könnte, ob ein Computer, also eine Maschine, ein dem Menschen gleichwertiges Denkvermögen hätte. Quelle: Wikipedia
Im Gegenzug zum Begriff der künstlichen Intelligenz, die mit dem Aufkommen der ersten Computer entstand, ist der Begriff Data Science (DS, zu Deutsch Datenwissenschaft) in der heutigen Form erst seit Beginn des 21. Jahrhunderts bekannt. Ziel ist die Extraktion von Wissen aus Daten. Dazu bedient sich die DS statistischer und mathematischer Methoden. Erst die technischen Möglichkeiten des systematischen Sammelns von digitalen Daten und die Zunahme der Rechengeschwindigkeit erlaubten die Entstehung einer solchen Disziplin.
Als Machine Learning (ML, zu Deutsch maschinelles Lernen) bezeichnet man Algorithmen, die durch Trainieren von mathematischen Modellen aus Daten Muster erkennen, die wiederum für Prognosen verwendet werden. Um aus Daten schnell Einsichten zu gewinnen, bedient sich die Data Science des maschinellen Lernens. Dabei ist das Anwenden der richtigen Algorithmen zur Beantwortung wichtiger Geschäftsfragen von wesentlicher Bedeutung. Im Bereich der künstlichen Intelligenz wiederum macht man sich die Fähigkeit, aus Erfahrungsdaten zu lernen, ebenfalls die Algorithmen des maschinellen Lernens zunutze.
Eine Untergruppe der Modelle, darunter die neuronalen Netze, gehört zur Kategorie des Deep Learning (DL, zu Deutsch tiefgehendes Lernen). Anders als im restlichen Teil des maschinellen Lernens wird hier kein oder nur geringes explizites Wissen über das zu lösende Problem vorausgesetzt. Das Wissen wird über mehrere Schichten hinweg berechnet, die sehr komplex miteinander interagieren, sodass sich nur implizites Wissen generieren lässt. Das System kann oder weiss also etwas, ohne zu wissen, wie. Mit Deep Learning werden typischerweise Aufgaben wie Bildund Spracherkennung gelöst.
Data Science selbst umfasst mehr als Algorithmen, da es hier auch um die Big-Data-Architektur und die wirtschaftliche Sicht geht, die einen starken Einfluss auf die Ausrichtung der Datenanalyse und deren Strategie im Unternehmen hat. Indes ist auch KI nicht allein auf die ML-Algorithmen gestützt. Zwar werden neue Regeln mit Machine Learning aus Daten gelernt. Es werden aber weitere Algorithmen der Logik verwendet, um Regeln abzuleiten oder bewertete Handlungsmöglichkeiten mit numerischen Verfahren zu optimieren. Auch Bereiche der Robotik sind bei der KI angesiedelt, die sich nur in kleinen Teilen mit Machine Learning überlappen. Eine Herausforderung ist das Entwerfen eines KI-Systems, das nicht nur eine spezifische, sondern mehrere Aufgaben lösen kann. Es hat sich gezeigt, dass Expertensysteme, die spezifische Aufgaben in einem gewissen Kontext lösen, ziemlich gut mithilfe von ML-Algorithmen gebaut werden können. So gibt es zum Beispiel den IBM Watson in verschiedenen Ausführungen: einmal als Expertensystem für die Unterstützung von Onkologen, ein anderes Mal als Expertensystem, das neue innovative Rezepte kreiert. Überhaupt treten kognitive Aufgaben wie Bild-, Textund Spracherkennung in vielen Problemstellungen auf, deren Lösungen als Bausteine eines Systems benutzt werden.
Das Potenzial der Cloud liegt darin, die Lösung dieser Aufgaben als unterschiedliche Dienste anzubieten. Genau dies tut beispielsweise Microsoft mit seinen Cognitive Services, einer Art Artificial Intelligence as a Service (AIaaS). Ein weiterer Vorteil von AIaaS kann sein, dass sich etwa Bildklassifizierungen durch einen Feedback- Loop verbessern. Hingegen kann ein unkontrolliertes Trainieren der Modelle sehr gefährlich sein. Das zeigte sich am Beispiel von Tay, einem Chatbot von Microsoft, dessen Tweets immer rassistischer und sexistischer wurden. Dies verdeutlicht gut, dass zumindest bis heute Moral oder Ethik nicht ohne Einwirkung und Steuerung des Menschen in einer künstlichen Intelligenz Einzug findet.
den Fachabteilungen – beispielsweise Controller, Marketing-, HR-Fachleute oder etwa Verkäufer – sehr schnell weit kommen und bottom-up Resultate für neue Ideen liefern können. Es braucht auch nicht gleich zwanzig Jahre Vergangenheitsdaten, um sich dem Thema zu nähern – wichtig ist aber insbesondere die Datenqualität, ohne die keine Analyse Sinn macht. Bei aller Begeisterung für Analytics, Data Science oder künstliche Intelligenz ist es wichtig, das Thema auch top-down konzeptionell anzugehen, um die Entstehung von Schatten-IT zu verhindern und die Einhaltung von Strukturen und Prozessen der IT und damit die Sicherstellung der Unterstützung der Unternehmensstrategie durch die IT zu gewährleisten.
Marcel Messerli, Data Scientist, IT-Logix, Zürich.